Retrouvez le livre sur le site de l’éditeur, et dans toutes les bonnes libraires :
Qu’est-ce que Power Query et M ?
Power Query permet l’extraction, la transformation et le chargement de données depuis une multitude de sources vers les deux outils principaux que sont Power BI et Excel. C’est surtout l’étape de transformation qui va nous intéresser dans cet ouvrage : les plus simples consistent à filtrer les lignes, choisir les champs ou encore vérifier le type de la donnée. Mais il est souvent nécessaire de nettoyer les données (harmoniser les champs de type texte, supprimer les valeurs nulles ou une ligne de total…), de créer de nouveaux champs, de calculer de nouveaux indicateurs ou de scinder un champ complexe en plusieurs valeurs distinctes.
M est le langage de programmation disponible dans Power Query qui permet de travailler plus vite et d’aller plus loin.
J’ai adopté dans ce livre une approche mixte : laisser l’interface graphique générer le code et y apporter des améliorations en code M lorsque cela est utile, tant en termes de rapidité de conception qu’en termes de possibilités de transformation.
Ce que vous trouverez dans ce livre
Le but de cet ouvrage est de vous permettre d’acquérir une très bonne maîtrise de Power Query et les notions fondamentales du langage M, à travers une alternance de bases théoriques indispensables pour en comprendre le fonctionnement et de nombreux exercices de mise en pratique.
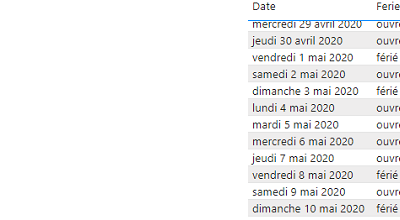
Dans le premier chapitre, nous nous intéressons aux connecteurs. Nous évoquons un certain nombre de cas courants (fichier Excel, fichier Excel avec plusieurs feuilles, plusieurs fichiers Excel, tableaux croisés), puis nous voyons l’import de fichiers plats (TXT, JSON), l’import à partir de bases de données et l’import de données issues du Web. Nous évoquons aussi les jeux de données (datasets) et les données issues de la Power Platform.
Le deuxième chapitre est consacré au nettoyage et à la préparation des données. Nous y voyons comment transformer des colonnes, dépivoter un tableau croisé, transformer successivement du texte, des numériques puis des dates, comment ajouter des colonnes, combiner (associer) des tables, comment gérer les erreurs de chargement. Nous voyons aussi comment accéder au code M, comment le lire et comment, après avoir utilisé l’interface graphique, reproduire ou améliorer l’opération à l’aide du code M.
Le troisième chapitre vous propose d’aller plus loin avec Power Query et M en travaillant sur les étapes de transformation, avec l’organisation des requêtes, les paramètres, les filtres dynamiques, l’agrégation des tables. Nous évoquons également dans ce chapitre le modèle « en étoile » qui est la structure de données recommandée.
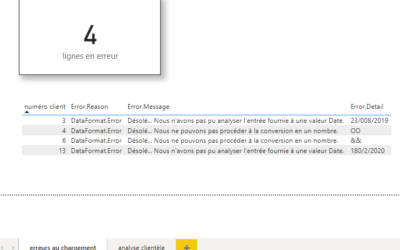
Le quatrième chapitre se concentre sur les erreurs au chargement des données : comment les déceler, comment générer un rapport d’erreurs pour les corriger.
Dans le chapitre suivant, nous plongeons dans le code M pour mieux comprendre sa structure, ses entités, créer des fonctions personnalisées, utiliser l’actualisation incrémentielle, découvrir des cas complexes de transformation ou d’extraction de données à partir du Web.
Le livre se termine par un court chapitre dans lequel nous évoquons l’installation et l’utilisation de R ou de Python dans Power Query.
Bonne lecture !